1. DataFrame을 이용한 시각화
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 1. 딕셔너리를 이용한 DataFrame 생성
np.random.seed(100)
data = {'a':np.arange(50),
'c':np.random.randint(0,50,50),
'd':np.random.randn(50)
}
data['b'] = data['a'] + 10 *np.random.randn(50)
data['d'] = np.abs(data['d']) *
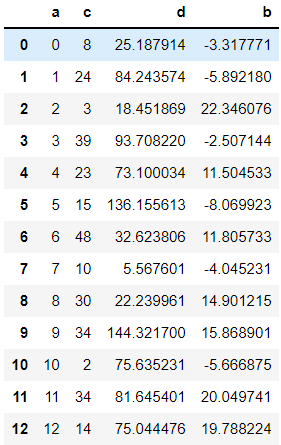
pd.DataFrame(data)
2. 산점도 그래프를 이용한 시각화 .. scatter
산점도 그래프는 scatter() 함수를 사용한다.
X, Y 축에 해당하는 데이터의 상관관계 ... 얼마나 많이 분포 혹은 흩어져 있는지를 한 눈에 확인 가능
X, Y 두 개의 축을 기준으로 데이터가 얼마나 퍼져있는지를 알 수 있다.
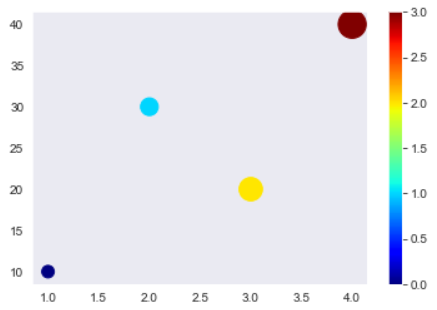
plt.scatter([1,2,3,4], [10, 30, 20, 40], s=[100, 200, 350, 500], c=range(4), cmap='jet') # 구글에서 pyhton cmap 검색해서 튜토리얼
plt.colorbar() # strong과 color의 맵핑을 해준다
plt.show()
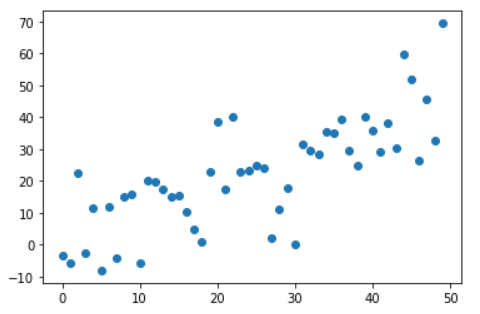
plt.scatter('a','b',data=data)
plt.show()
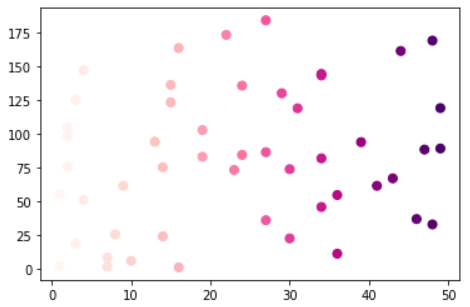
# plt.scatter('c','d',data=data, c='c' , s='d')
# scatter 자체는 legend를 사용할 수 없다.
plt.scatter('c','d',data=data, c='c' , s=50, cmap="RdPu")
plt.show()
import seaborn as sns
cutoff = (data['a'] > 25) & (data['b'] > 20)
sns.set_style('dark')
data['color'] = np.where(cutoff==True, "red", "blue")
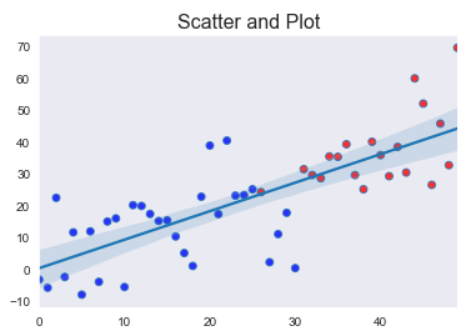
sns.regplot(x = data['a'],
y = data['b'],
scatter_kws={'facecolors' : data['color']}
)
plt.title("Scatter and Plot", fontsize=16)
plt.show()
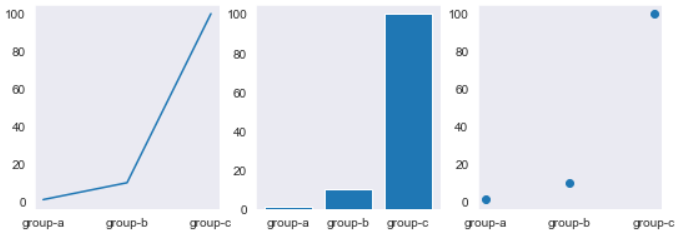
3. Subplot으로 plot(), scatter(), bar() 동시에 시각화
names = ['group-a', 'group-b', 'group-c'] # X 값으로 이용
values = [1, 10, 100] # Y 값으로 이용
plt.figure(figsize=(9,3)) # 3등분 하기 쉽도록 전체 영역을 새롭게 잡아놓는다.
plt.subplot(131) # 1개를 지정하는 3개 중에 1번째 라는 의미
plt.plot(names, values)
plt.subplot(132) # 1개를 지정하는 3개 중에 2번째 라는 의미
plt.bar(names, values)
plt.subplot(133) # 1개를 지정하는 3개 중에 3번째 라는 의미
plt.scatter(names, values)
plt.show()
'데이터과학자 - 강의 > 데이터분석' 카테고리의 다른 글
| 210728 시각화 : MatPlot - 1 (0) | 2021.08.02 |
|---|---|
| 210727 pandas의 pivot table (0) | 2021.08.01 |
| 210726 pandas의 groupby (0) | 2021.07.27 |
| 210723 pandas의 concat, merge (0) | 2021.07.27 |
| 210722 pandas의 DataFrame -2, NaN (0) | 2021.07.22 |