DataFrame - 데이터 병합¶
- Concat
단순히 하나의 DataFrame에 다른 DataFrame을 연속적으로 붙이는 방법
이 경우에는 두 DataFrame이 서로 동일한 인덱스, 컬럼을 가지고 있는 경우가 대부분이다
위, 아래로 연결되는 방식이 기본이지만 좌, 우 연결도 가능하다
outer join이 기본으로 동작
key를 이용해 Concat을 활용해서 사용한다. - Merge
1. pandas의 concat
import numpy as np
import pandas as pd
from pandas import DataFrame, Series
import matplotlib.pyplot as plt
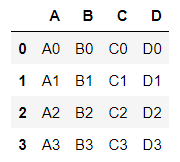
df1 = DataFrame({
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3'],
})
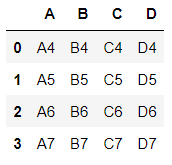
df2 = pd.DataFrame({
'A':['A4', 'A5', 'A6', 'A7'],
'B':['B4', 'B5', 'B6', 'B7'],
'C':['C4', 'C5', 'C6', 'C7'],
'D':['D4', 'D5', 'D6', 'D7'],
})
df1, df2 데이터를 가만히 봐보자
어떻게 병합하는게 좋을까?
==> 상하 연결
==> pandas에서 제공하는 함수 concat()
::
결과를 확인하면
0123, 0123 동일한 인덱스 값이 그대로 반복된다.
ignore_index = True 옵션을 지정한다.
# result1 = pd.concat([df1, df2])
result1 = pd.concat([df1, df2], ignore_index=True)
result1
좌우 병합은?
ignore_index=True 이거하면 해당 컬럼명이 인덱스로 대체된다
result2 = pd.concat([df1, df2], axis=1) # 행이 아닌 열로 합쳐진다.
result2 = pd.concat([df1, df2], axis=1, ignore_index=True)
result2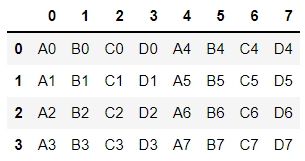
1-1. KEYS
각각 다른 데이터를 병합하는 것이니 출처를 표기해준다. ex)2020년 데이터 or 2021년 데이터
그룹핑, 세분화하는데 쓰인다
result2 = pd.concat([df1, df2], keys=['Female', 'Male']) # ignore_index=True 랑은 중복이 안되네
result2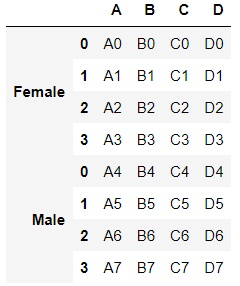
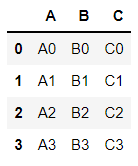
df3 = DataFrame({
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'],
'C':['C0','C1','C2','C3']
})
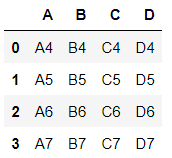
df4 = pd.DataFrame({
'A':['A4', 'A5', 'A6', 'A7'],
'B':['B4', 'B5', 'B6', 'B7'],
'C':['C4', 'C5', 'C6', 'C7'],
'D':['D4', 'D5', 'D6', 'D7'],
})
위 df3, df4 데이터는 행과 열 인덱스가 일치하지 않는 데이터프레임이다.
axis=0 을 기준으로 병합하기 때문에 concat은 상하로 데이터를 이어붙이게 될 것이다.
어떤 현상이 발생할까?
outer join이기 때문에 없는 부분을 NaN으로 채운다.
result3 = pd.concat([df3, df4], ignore_index=True) # join='outer' 가 default
result3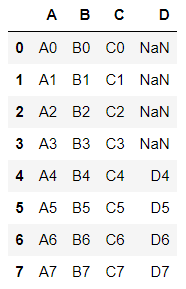
# 둘 다 공통적으로 가지고있는 열만 가지고 온다.
result4 = pd.concat([df3, df4], ignore_index=True, join='inner')
result4
2. pandas의 merge
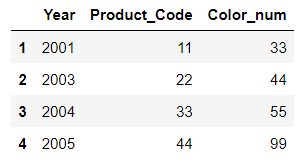
df1, df2는 인덱스만 다르고 모든 값을 동일하게 가지고 있다.
df3는 Color_num라는 다른 column을 가지고 있다.
df1 = DataFrame({ 'Year':[2001,2002,2003,2004],
'Product_Code':[11,22,33,44],
'Price':[10000,20000,30000,40000]},
index=list('1234'))
df2 = DataFrame({ 'Year':[2001,2002,2003,2004],
'Product_Code':[11,22,33,44],
'Price':[10000,20000,30000,40000]},
index=list('5678'))
df3 = DataFrame({ 'Year':[2001,2003,2004,2005],
'Product_Code':[11,22,33,44],
'Color_num':[33,44,55,99]},
index=list('1234'))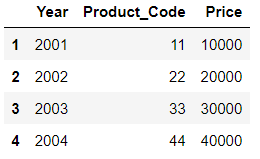
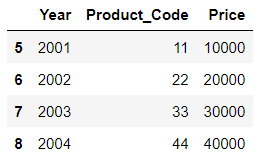
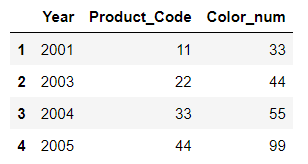
df1, df2를 merge
1. 표현법이 concat과 다르다 ... [ ] 들어가지 않는다...
2. 인덱스와 상관없이 병합되고(*좌우병합이기 때문) 값이 같다면 중복표기되지 않는다.
result01 = pd.merge(df1, df2)
result01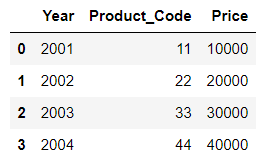
df1_1 = DataFrame({ 'Year':[2001,2002,2003,2004],
'Product_Code':[11,22,33,44],
'Price':[15000,25000,35000,45000]},
index=list('1234'))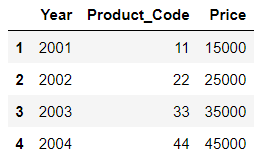
df1_1 와 df1을 merge.... on을 사용하지 않으면 아무것도 나오지 않는다.
병합할 때의 기준이 되는 컬럼을 지정하는 것이 on이다
기준이 되는 컬럼 외에는 다 중복으로 데이터가 표기된다.
result02_1 = pd.merge(df1, df1_1), on=['Year']
result02_1
result02_2 = pd.merge(df1, df1_1, on=['Year'])
result02_2
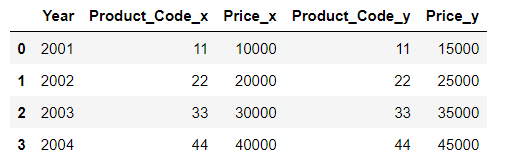
result03 = pd.merge(df1, df1_1, on=['Year', 'Product_Code'])
result03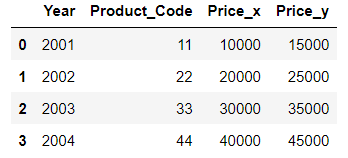
3. set_index()
특정한 컬럼을 인덱스로 지정함으로써
DataFrame을 좀 더 깔끔하고 직관적으로 볼 수 있다.
result03.set_index('Year', inplace=True)
result03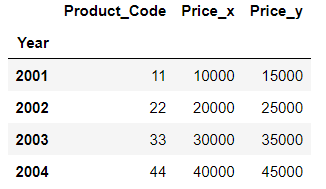
4. df1, df3 merge
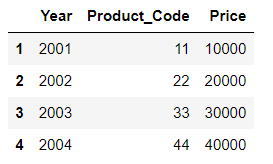
how 옵션이 있다... 어떻게 merge 할 것인가? concat의 join= 과 같다
여기서 inner가 dafault 이다.
result05 = pd.merge(df1, df3, how='outer', on='Year')
result05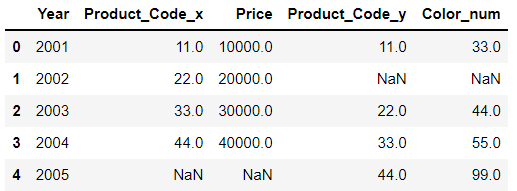
매개변수 중 left(df1)의 Year의 모든 값을 살리면서 join
result06 = pd.merge(df1, df3, 'left', on='Year')
result06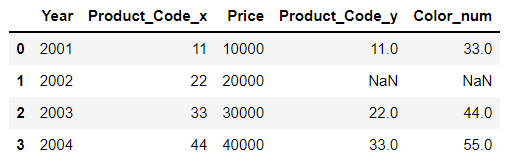
'데이터과학자 - 강의 > 데이터분석' 카테고리의 다른 글
| 210727 pandas의 pivot table (0) | 2021.08.01 |
|---|---|
| 210726 pandas의 groupby (0) | 2021.07.27 |
| 210722 pandas의 DataFrame -2, NaN (0) | 2021.07.22 |
| 210721 pandas의 DataFrame (0) | 2021.07.22 |
| 210721 numpy.ndarray-2, pandas.Series (0) | 2021.07.21 |