하둡 공홈 도움말의
============================================================================
MapReduce Tutorial 실행
1. 디렉토리 생성
$HADOOP_HOME/bin/hadoop fs -mkdir -p /user/joe/wordcount/input/
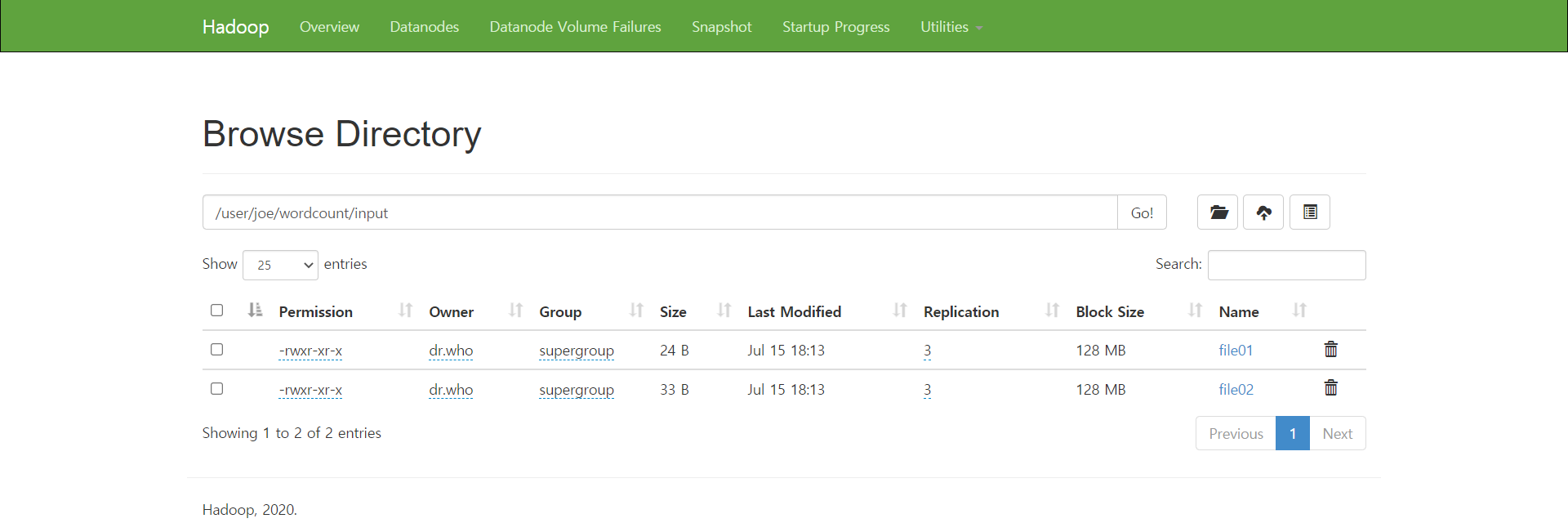
2. /test에 file01, file02와 wc2.jar 파일두기
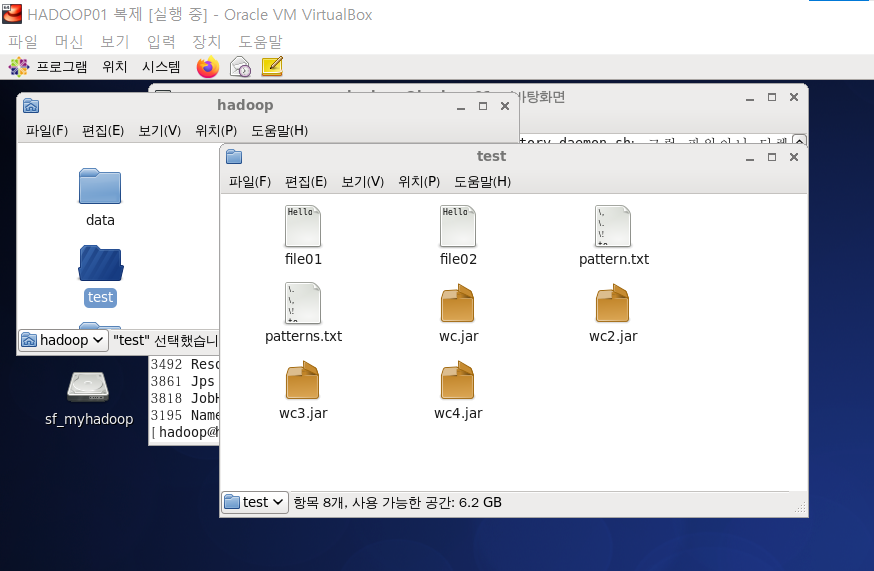
3. 생성한 디렉토리에 파일 업로드
cd ~/test
[hadoop@hadoop01 test]$ $HADOOP_HOME/bin/hadoop fs -put file01 /user/joe/wordcount/input
[hadoop@hadoop01 test]$ $HADOOP_HOME/bin/hadoop fs -put file02 /user/joe/wordcount/input
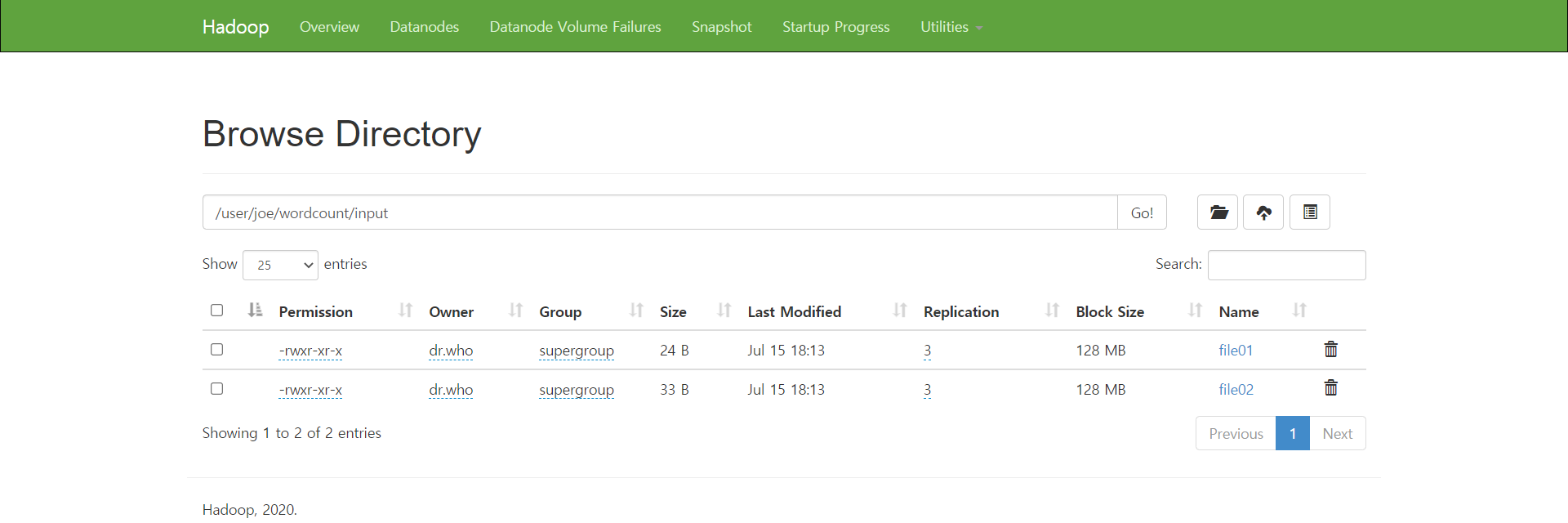
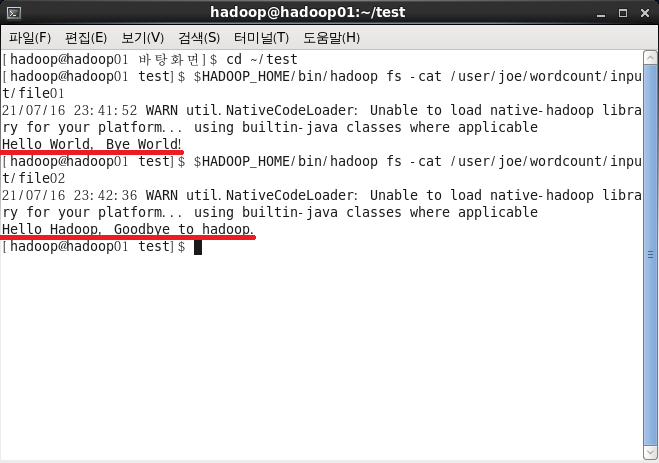
4. 올린 파일 읽어오기
$HADOOP_HOME/bin/hadoop fs -cat /user/joe/wordcount/input/file01
$HADOOP_HOME/bin/hadoop fs -cat /user/joe/wordcount/input/file02
5. wc2.jar를 실행하여 MapReduce 실행 후 결과확인
$HADOOP_HOME/bin/hadoop jar wc.jar /user/joe/wordcount/input /user/joe/wordcount/output
$HADOOP_HOME/bin/hadoop fs -cat /user/joe/wordcount/output/part-r-00000
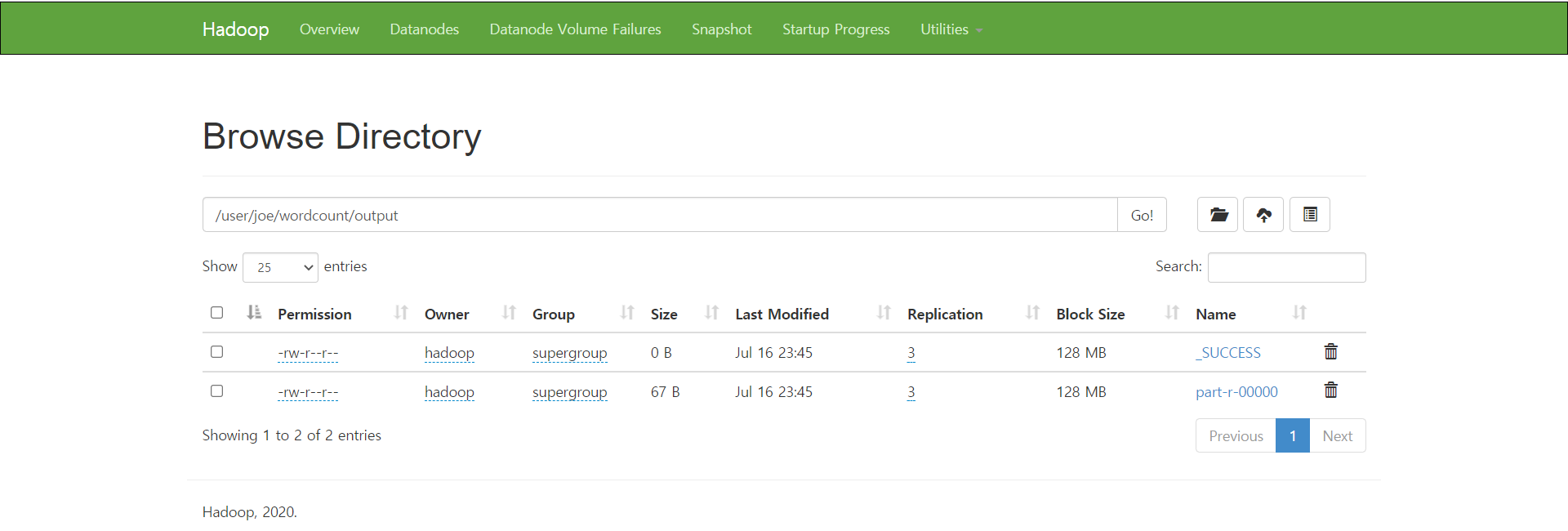

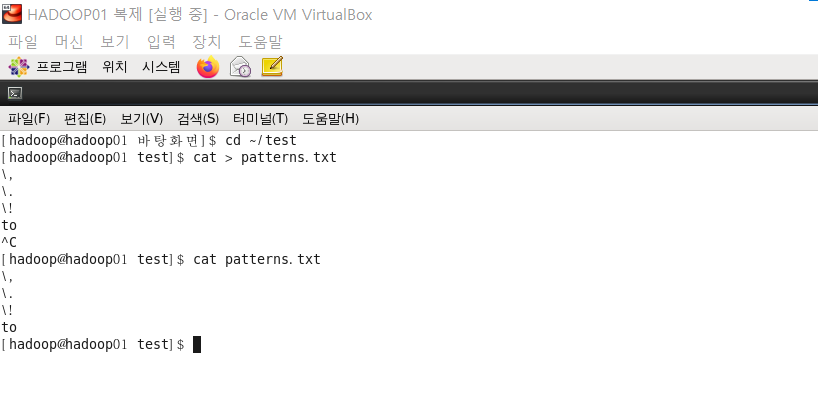
6. home/hadoop/test 경로에 예외처리할 내용을 담은 patterns.txt 파일 생성
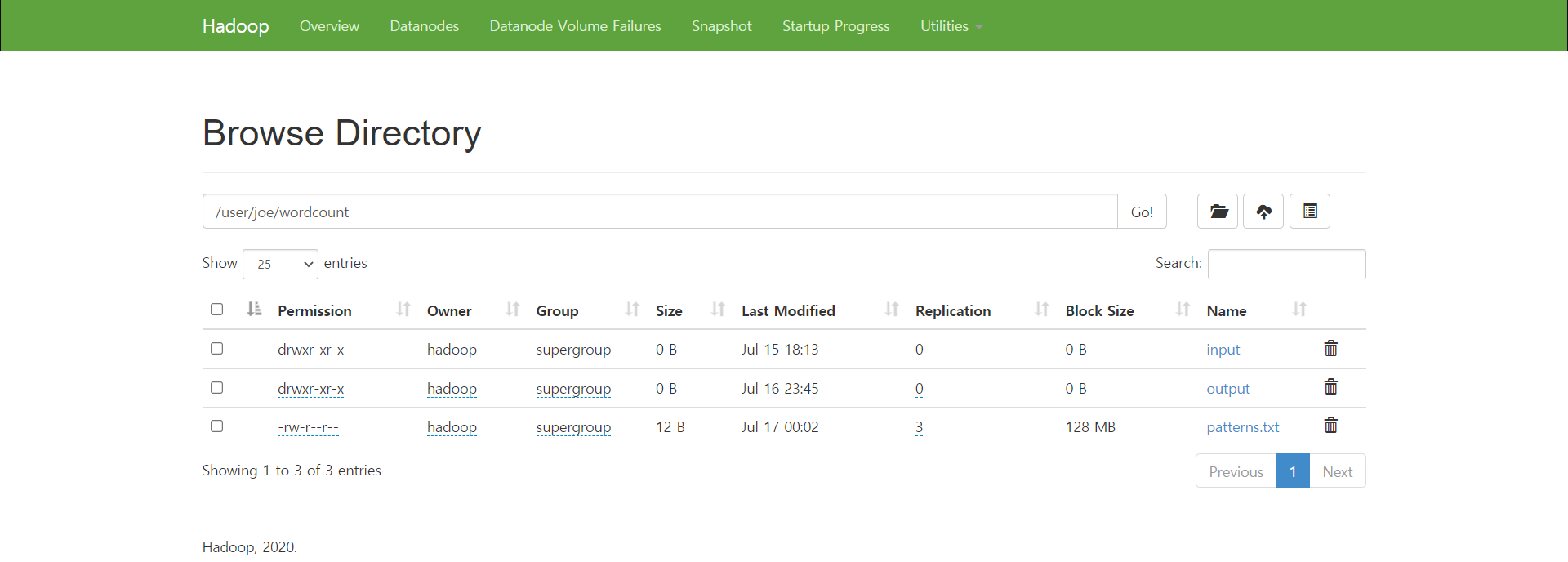
7. patterns.txt 파일을 디렉토리에 업로드
[hadoop@hadoop01 test]$ $HADOOP_HOME/bin/hadoop fs -put patterns.txt /user/joe/wordcount
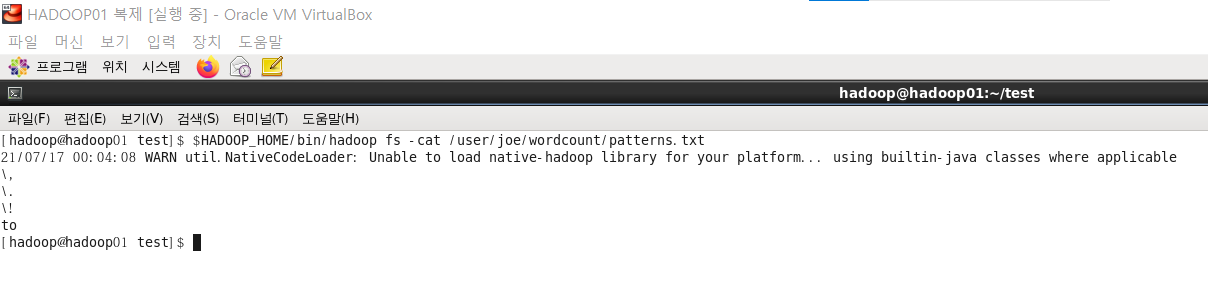
8. 패턴 읽어보기
[hadoop@hadoop01 test]$ $HADOOP_HOME/bin/hadoop fs -cat /user/joe/wordcount/patterns.txt
9. 구문 실행 및 결과 확인
$HADOOP_HOME/bin/hadoop jar wc2.jar
-Dwordcount.case.sensitive=true /user/joe/wordcount/input /user/joe/wordcount/output1
-skip /user/joe/wordcount/patterns.txt
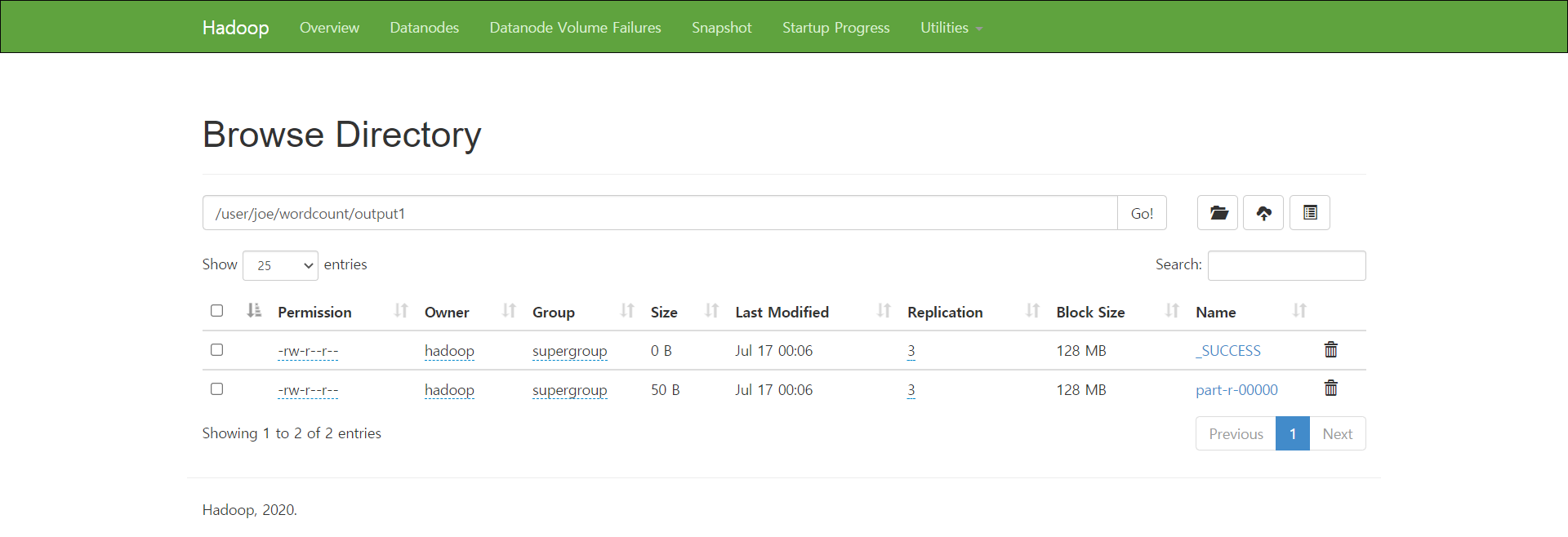
$HADOOP_HOME/bin/hadoop fs -cat /user/joe/wordcount/output1/part-r-00000
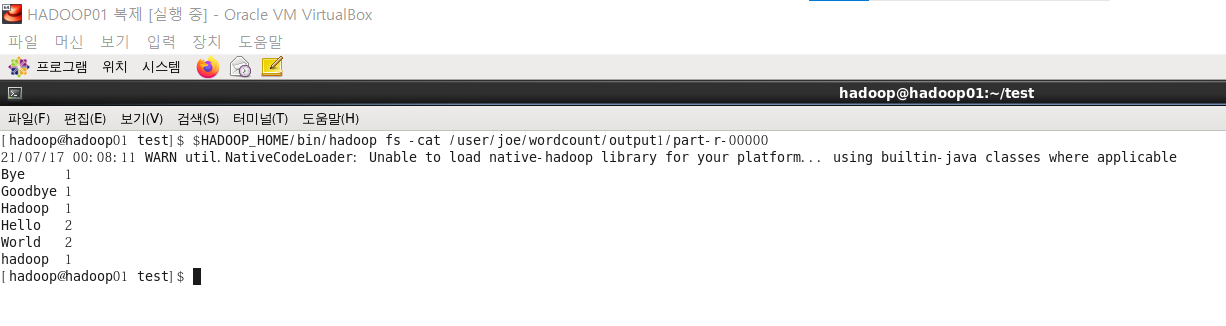
-Dwordcount.case.sensitive=true 옵션으로 대소문자를 구별하여 Hadoop과 hadoop이
다르게 카운트 된 것을 확인할 수 있다.
10. 구문 실행 및 결과 확인
$HADOOP_HOME/bin/hadoop jar wc2.jar
-Dwordcount.case.sensitive=false /user/joe/wordcount/input /user/joe/wordcount/output2
-skip /user/joe/wordcount/patterns.txt
$HADOOP_HOME/bin/hadoop fs -cat /user/joe/wordcount/output1/part-r-00000
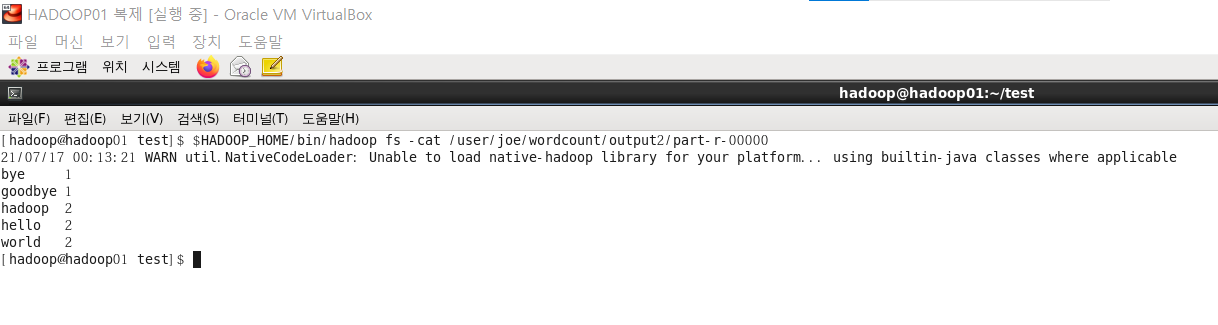
9.의 결과와는 다르게 대소문자를 구별하지 않아 hadoop의 카운트가 2가 된 것을 확인할 수 있다.
'데이터과학자 - 강의 > hadoop & ecosystem' 카테고리의 다른 글
| 210713 Hadoop Namenode (0) | 2021.07.13 |
|---|---|
| 210712 Hadoop Cluster Setup, MapReduce Tutorial (0) | 2021.07.12 |
| 210710 Hadoop 설치 -2 (0) | 2021.07.12 |
| 210709 Hadoop 설치 -1 (0) | 2021.07.11 |
| 210708 - centOS 설치 (0) | 2021.07.10 |