210720 Anaconda, jupyter, numpy.ndarray
오늘부터 본격적으로 데이터분석, 딥러닝, 머신러닝 수업에 들어간다.
그 시작으로 필요한 설치를 진행했다.
============================================================================
1. Anaconda 설치
1-1. Anaconda 설치 파일 다운로드
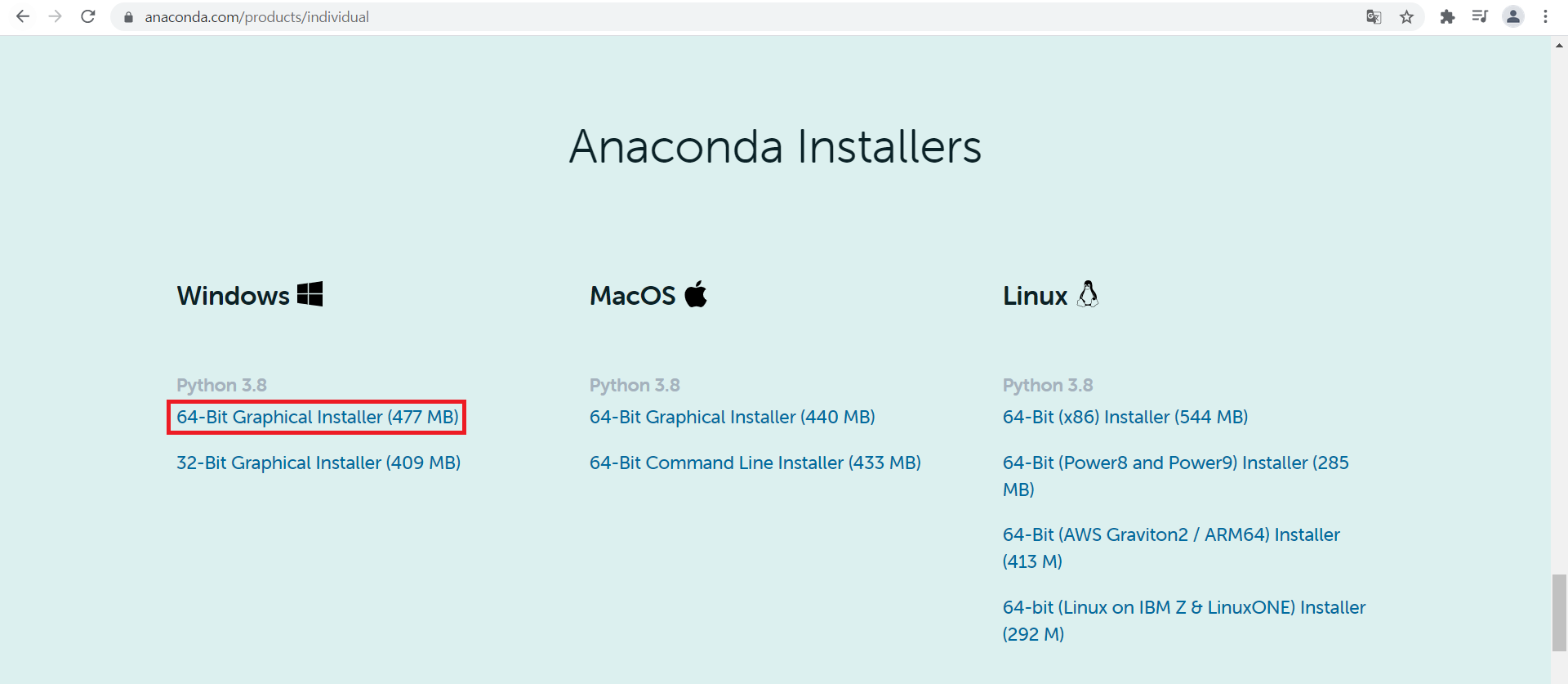
https://www.anaconda.com/products/individual
아나콘다 홈페이지의 메인 페이지 하단에서 운영체제에 맞는 설치 파일 다운
1-2 설치 진행
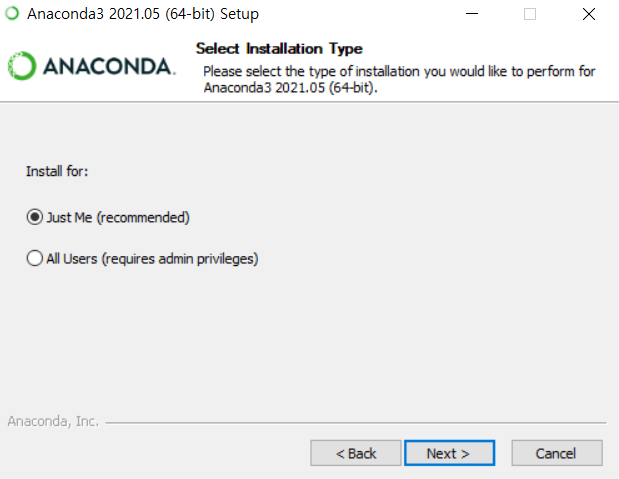
설치 파일을 우클릭 - 관리자 권한으로 실행하여 설치를 진행한다.
상단 이미지처럼 권한만 Just Me와 경로만 원하는 경로로 변경하고 default설치를 진행했다.
============================================================================
2. jupyter 실행 설정
2-1. 바탕화면에 바로가기 생성
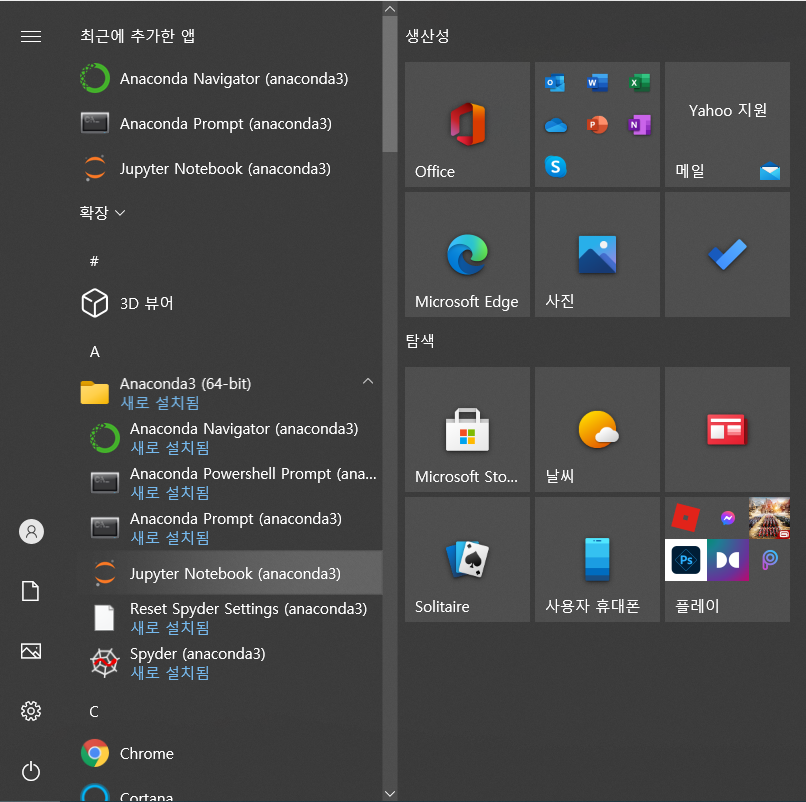
윈도우 메뉴를 실행해보면 Anaconda가 설치되어 올라온다.
Jupyter Notebook을 그대로 드래그해 바탕화면에 바로가기를 생성한다.
2-2. 바로가기 속성 변경
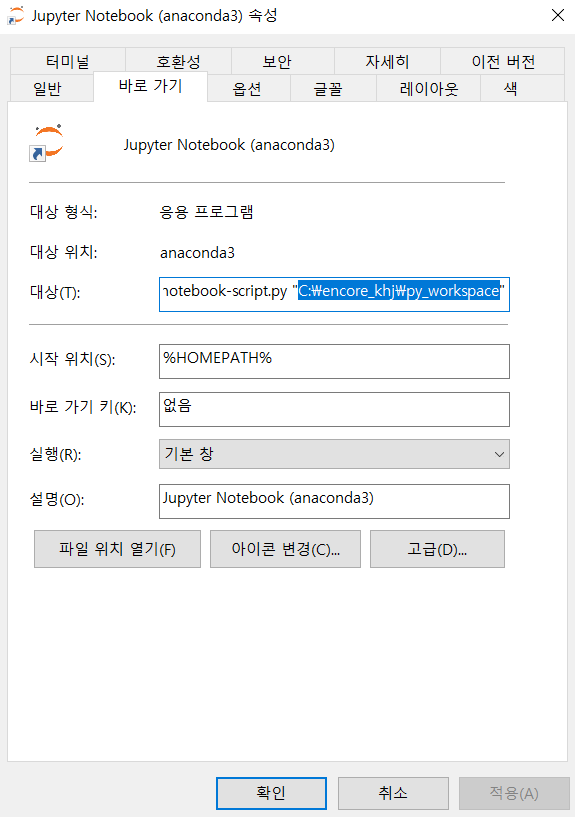
우클릭 ㅡ 속성에 들어가면 해당화면이 바로뜬다. 여기서 " " 안이 다른 내용으로 채워져 있는데
주 작업경로로 변경해주고 실행하면 된다.
============================================================================3. Numpy 배열 생성하기
Numpy는 Numeric Python의 줄임말
수학분야와 관련된 통계, 연산 작업시에 필요한 라이브러리
과학 계산 컴퓨팅과 데이터 분석에 필요한 가장 기본적인 패키지
Numpy배열은 리스트와 거의 흡사하지만
연산 속도가 빠르고 메모리 효율성이 높아서 대용량 데이터를 다루는데 성능상 우위에 있다.
사용하기 전에 라이브러리 모듈을 import 해야 한다.
1) array() 사용
2) random 랜덤함수 사용
3-1. 리스트와 numpy배열을 각각 생성해 두 개를 비교해보자
1.
리스트는 출력 결과가 [ ]안에 들어오고 각 요소들이 ,로 구분된다.
np배열은 출력 결과가 [ ]안에 들어오고 각 요소들이 그냥 나열된다.
2.
np배열의 타입은 ndarray타입 = ndarray 클래스 : 다차원 행렬구조를 지원하는 Numpy의 핵심 클래스
3.
리스트는 원본이 안바뀐다. 원본을 카피해서 새로운걸 만든다.
np배열은 원본뷰가 바뀐다.
메모리 활용적인 성능면에서는 np배열이 성능이 좋아진다.
import numpy as np
myList = [4,5,6,7]
myArr = np.array(myList)
print(myList)
print(myArr)
print(type(myList))
print(type(myArr))
# ========================================================================
list_sub = myList[1:3] # 슬라이싱(숫자일 때는 뒷 부분 숫자가 포함되지 않는다)
print(list_sub)
arr_sub = myArr[1:3]
print(arr_sub)
list_sub[0] = -5
arr_sub[0] = -5
print(list_sub)
print(arr_sub)
# ========================================================================
print(myList)
print(myArr)
# result==================================================================
[4, 5, 6, 7]
[4 5 6 7]
<class 'list'>
<class 'numpy.ndarray'>
# ========================================================================
[5, 6]
[5 6]
[-5, 6]
[-5 6]
# ========================================================================
[4, 5, 6, 7]
[ 4 -5 6 7]
3-2. random 함수 사용
a = np.random.rand(5)
print(a)
print(type(a))
b = np.random.randint(1,10,5)
print(b)
c = np.random.randn(10) # 가우시안 표준분포 값
print(c)
# result =================================================
[0.11422413 0.52544893 0.18869529 0.45081129 0.04235887]
<class 'numpy.ndarray'>
[7 1 1 4 6]
[ 2.12486086 -0.21495564 0.65277968 -0.17930631 1.42798995
-1.80503814 -0.14268248 0.58640306 -2.55503308 -1.37679103]
3-3. np배열 생성과 동시에 초기화
zeros(), ones(), arange() 함수 사용
# 0으로 초기화
# 0값으로 이뤄진 크기가 10인 배열 생성
# 기본이 실수형이다
az = np.zeros(10)
print(az)
print(type(az))
# 1값으로 이뤄진 크기가 10인 배열 생성
ao = np.ones(10)
print(ao)
# 5값으로 이뤄진 크기가 10인 배열 생성
az5 = np.zeros(10) + 5
print(az5)
ao5 = np.ones(10) * 5
print(ao5)
# eye()
ae = np.eye(3)
print(ae)
# arange()
print(np.arange(3))
print(np.arange(3, 7))
print(np.arange(3, 10 ,2))
# full()
afull = np.full((5, 5), -11)
print(afull)
# result ===============================================================
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
<class 'numpy.ndarray'>
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[5. 5. 5. 5. 5. 5. 5. 5. 5. 5.]
[5. 5. 5. 5. 5. 5. 5. 5. 5. 5.]
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
[0 1 2]
[3 4 5 6]
[3 5 7 9]
[[-11 -11 -11 -11 -11]
[-11 -11 -11 -11 -11]
[-11 -11 -11 -11 -11]
[-11 -11 -11 -11 -11]
[-11 -11 -11 -11 -11]]
============================================================================
4. Numpy 배열의 속성과 함수
리스트는 여러가지 자료형 저장이 가능하다.
np배열은 하나의 자료형만 저장할 수 있다.
만약에
숫자와 문자가 동시에 저장된다면
capacity가 더 큰 문자로 변환되어서 저장된다.
np배열은 이러한 제약(동일한 datatype만 저장가능)을 가지는 대신에
내부 원소에 대한 접근과 반복문 실행이 빨라지도록 설계되어져 있다.
값의 타입을 지정해서 저장할 때는 dtype 속성을 사용해서 저장한다.
int32, int64, float32, float64 등 지정 가능
import numpy as np
myList = [1, 2, 3, '4', 5, 6]
print(myList)
print(type(myList))
myArr = np.array([1, 2, 3, '4', 5])
print(myArr)
print(type(myArr))
myArr2 = np.array([1, 2, 3, 4.0, 5])
print(myArr2)
print(type(myArr2))
# myArr3 = np.array([1,2,3,4], dtype='float')
myArr3 = np.array([1,2,3,4], dtype=np.float64)
print(myArr3)
print(type(myArr3))
# result ==============================================================
[1, 2, 3, '4', 5, 6]
<class 'list'>
['1' '2' '3' '4' '5']
<class 'numpy.ndarray'>
[1. 2. 3. 4. 5.]
<class 'numpy.ndarray'>
[1. 2. 3. 4.]
<class 'numpy.ndarray'>
- ndim, shape, reshape, size, type, dtype
- Numpy배열의 타입은 ndarray 클래스이다.
클래스는 다양한 field와 method를 가지고 있고
ndim, shape, size, dtype은 필드로도 메소드로도 사용가능하다.
reshape, type은 메소드로만 사용 가능
print(myArr)
print(np.ndim(myArr)) # 몇 차원인지 리턴
print(np.shape(myArr)) # 몇 행, 몇 렬인지 알 수 있다.
print(np.size(myArr)) # 요소의 개수를 리턴
print(type(myArr))
print('*' * 30)
print(myArr.ndim)
print(myArr.shape)
print(myArr.size)
print(myArr.dtype)
print('*' * 30)
# np배열의 원소 값의 타입을 한 번에 바꿀 수 있다. astype()
# astype(), type(), dtype 각각 구분해서 적용할 수 있어야 한다.
myArr_1 = myArr.astype(np.float64)
print(myArr_1)
print(myArr_1.dtype)
print('*' * 30)
arr1 = np.arange(32).reshape(8, 4)
print(arr1)
#result ======================================================
['1' '2' '3' '4' '5']
1
(5,)
5
<class 'numpy.ndarray'>
******************************
1
(5,)
5
<U11
******************************
[1. 2. 3. 4. 5.]
float64
******************************
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]]
============================================================================
5. 랜덤 함수와 seed값 설정하기
특정한 시작 숫자를 정해주어서 난수를 발생시키면 고정적인 난수가 발생된다.
결과 확인 시 시작 숫자가 동일하다면 테스트 결과 확인할 때 용이하다.
seed() 함수에 정수를 지정하면 된다
# 실행할 때마다 값이 바뀐다...
arr2 = np.random.randn(4,4)
print(arr2)
# 시드 값은 0 혹은 양의 정수를 지정하면 된다.
np.random.seed(0)
arr3 = np.random.randn(4, 4)
print(arr3)
# reshape 할 때는 지정하는 값을 정확하게 주어야 한다. 아니면 에러발생
# 시드값은 한 번만 주면 계속 적용된다.
arr4 = np.random.randint(10, 20, 16).reshape(4, 4)
arr4
============================================================================
6. 인덱싱과 조건 슬라이싱
# 1. 논리연산자 (<, >, !=, == 등) 사용
print(arr3[arr3>0])
print(arr3[arr3<0])
# 2. 0보다 작은 값들을 전부 다 0으로 바꿔보자
arr3[arr3<0] = 0
print(arr3)
# result ===================================================
[1.76405235 0.40015721 0.97873798 2.2408932 1.86755799 0.95008842
0.4105985 0.14404357 1.45427351 0.76103773 0.12167502 0.44386323
0.33367433]
[-0.97727788 -0.15135721 -0.10321885]
[[1.76405235 0.40015721 0.97873798 2.2408932 ]
[1.86755799 0. 0.95008842 0. ]
[0. 0.4105985 0.14404357 1.45427351]
[0.76103773 0.12167502 0.44386323 0.33367433]]# 3. where 함수를 적용 ... 조건부 슬라이싱
# arr3가 0보다 크다가 참이면 arr3을 그대로 리턴하고 거짓이면 -1을 리턴
arr3_1 = np.where(arr3 > 0, arr3, -1) # 삼항연산자랑 비슷
arr3_1
# result ==========================================================
array([[ 1.76405235, 0.40015721, 0.97873798, 2.2408932 ],
[ 1.86755799, -1. , 0.95008842, -1. ],
[-1. , 0.4105985 , 0.14404357, 1.45427351],
[ 0.76103773, 0.12167502, 0.44386323, 0.33367433]])# 중요!!!
arr5 = np.array([[1,2], [3,4], [5,6]])
bool_idx = arr5 > 2
print(bool_idx)
print(arr5[bool_idx])
# result===========================================================
[[False False]
[ True True]
[ True True]]
[3 4 5 6]