python, oracle, mongoDB 미니프로젝트
1. 주식데이터를 api로 크롤링해서
2. 오라클에 한번 넣었다가 json 파일로 만들고
3. mongoimport로 mongoDB에 넣었다가
4. 맵리듀스한 결과를 추출해서 csv로 만들어서
5. plotly로 시각화
배운 것을 활용하기 위해 굳이 db를 왔다갔다 했음
============================================================================
1. 주식데이터 API 크롤링
http://data.krx.co.kr/contents/MDC/MDI/mdiLoader/index.cmd?menuId=MDC0201020201

위 주소에서 세부안내 - 업종분류 현황의 자료를 크롤링한다. mongoDB에서 업종명별로 그룹화해서 결과를 뽑기 위함.

F12를 눌러 개발자 도구의 Network 탭을 열고 조회를 누르면 데이터를 어디로 요청했는지 나온다.
URL과 POST방식으로 값을 요청했음을 확인할 수 있다.
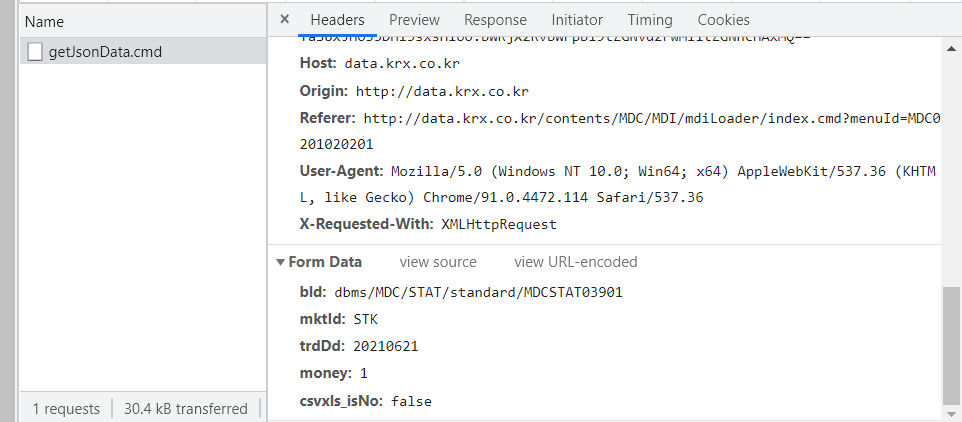
POST 방식으로 요청했으므로 Form Data는 하단에 따로 있다.
위에서 User-Agent는 현재 접속한 브라우저의 정보이며 크롤링에 필요하다.
def get_stock_data():
url = "http://data.krx.co.kr/comm/bldAttendant/getJsonData.cmd"
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'}
data = {"bld": "dbms/MDC/STAT/standard/MDCSTAT03901", # 주소에 넘겨줄 값
"mktId": "STK",
"trdDd": f"{datetime.date.today().strftime('%Y%m%d')}", # datetime.date.today().strftime('%Y%m%d')
"money": "1",
"csvxls_isNo": "false", }
response = requests.post(url, headers=header, data=data).json() # 주소에 값을 전달해주고 값을 받아 json으로 만든 부분!
return responseurl 변수는 상단 이미지 중에서 Request URL이고 header는 User-Agent, data는 Form Data이다.
requests.post로 값을 받아와 json형태로 변수에 저장한다.
data의 trdDd에는 날짜가 8자리로 들어가는데 오늘 날짜를 받아 8자리로 포맷팅시켰다.
단, 주말에는 장이 열리지 않아 값이 비게된다.
2. 정형 DB(oracle)에 넣기 원하는 column만 select하기
CREATE TABLE STOCK(
STOCK_CODE VARCHAR2(4000) PRIMARY KEY,
STOCK_NAME VARCHAR2(4000),
MARKET VARCHAR2(4000),
INDUSTRY_TYPE VARCHAR2(4000),
END_PRICE VARCHAR2(4000),
CONTRAST VARCHAR2(4000),
FLUCTUATION VARCHAR2(4000),
MARKET_CAPITALIZATION VARCHAR2(4000)
);테이블 구조. 가격과 시가총액들도 일단은 모두 문자열 형태로 저장한다.
def insert_oracle(response):
dsn = cx_Oracle.makedsn("localhost", 1521, 'xe') # oracle 주소를 입력
db = cx_Oracle.connect('SCOTT', 'TIGER', dsn) # oracle 접속 유저 정보
cur = db.cursor()
for i in response['block1']:
value_list = list(i.values())[:8] # 오라클에 넣을 값
try:
cur.execute("INSERT INTO STOCK VALUES(:1, :2, :3, :4, :5, :6, :7, :8)", value_list)
db.commit()
except:
pass
db.close()1. 에서 return받은 response를 넘겨받는다. json은 파이썬에서 dictionary와 맵핑되므로 values만 취해서 오라클에 넣는다.
종목코드가 primary key로 설정되어 있기 때문에 try로 insert를 하고 except에는 update 구문을 넣을 예정이었다.
3. oracle에서 원하는 column만 select해 값을 가져오고 json파일로 저장
def select_oracle():
dsn = cx_Oracle.makedsn("localhost", 1521, 'xe') # oracle 주소를 입력
db = cx_Oracle.connect('SCOTT', 'TIGER', dsn) # oracle 접속 유저 정보
cur = db.cursor()
cur.execute("SELECT STOCK_NAME, INDUSTRY_TYPE, FLUCTUATION, MARKET_CAPITALIZATION FROM STOCK") # oracle에서 만든 stock table에서 필요한 column들만 추출!
column = ["STOCK_NAME", "INDUSTRY_TYPE", "FLUCTUATION", "MARKET_CAPITALIZATION"] # dict 만들려고 컬럼명 만듬
rows = cur.fetchall() # SQL 결과를 받아옴
data = [] # dict를 저장할 빈 리스트 선언
for row in rows:
list_row = list(row)
list_row[2] = float(list_row[2])
list_row[3] = int(list_row[3].replace(',', ''))
data.append(dict(zip(column, list_row))) # column과 row를 묶어 dictionary를 만들어 data에 append함
data_json = {}
data_json['data'] = data
# json형식으로 파일 만들기 처리!
with open("../stock.json", "w", encoding='utf-8') as f:
json.dump(data_json, f, ensure_ascii=False)json의 key가 될 column을 설정하고 oracle에서 가져온 row와 zip으로 묶어 dictionary를 만든다.
이것을 파일로 만들어 저장
4. mongoimport로 mongoDB에 저장 후 map-reduce로 결과 가져오기
def mongo_import():
os.system('mongoimport --db stock -c stock --file stock.json')
def mr_return():
client = MongoClient('localhost', 27017) # mongo 접속
db = client.stock # stock db접속
res = db.stock.aggregate([
{"$unwind": "$data"},
{"$group": {"_id": "$data.INDUSTRY_TYPE", "sum": {"$sum": "$data.MARKET_CAPITALIZATION"}}}
])
res2 = db.stock.aggregate([
{"$unwind": "$data"},
{"$project": {"_id": 0}}
])
result = []
for i in res2:
result.append(i['data'])
with open("../stock.csv", 'w', encoding='utf-8') as f:
wr = csv.DictWriter(f, fieldnames=result[0].keys())
wr.writeheader()
wr.writerows(result)mongoDB에 접속해서 값을 넣은게 아니라 os로 실행해서 넣는다.
집계처리한 값으로 시각화를 구현하려고 했는데 plotly에 Rawdata를 주면 자체적으로 그런 집계를 내서
시각화한 결과를 돌려주는 것 같다.
그래서 집계처리한 결과는 사용되지 않는다....
mongoDB에서 모든 데이터를 가져와 csv형식으로 만들어 저장한다.
5. plotly로 시각화
def plotlyOnly():
df = pd.read_csv('../stock.csv')
df = pd.DataFrame(data=df)
fig = px.treemap(df,
path=['INDUSTRY_TYPE', 'STOCK_NAME'],
values='MARKET_CAPITALIZATION',
color='FLUCTUATION', color_continuous_scale='RdBu_r'
)
fig.data[0].texttemplate = "%{label}<br>등락률(전일대비):%{customdata}"
fig.show()csv파일을 통해 시각화를 만든다.

결과물
등락률에 따라 배경색이 결정되는데 장이 좋지 않았나보다.
전체코드
import requests
import datetime
import cx_Oracle
import json
import os
from pymongo import MongoClient
import csv
import pandas as pd
import plotly.express as px
# http://data.krx.co.kr/contents/MDC/MDI/mdiLoader/index.cmd?menuId=MDC0201020201
# 세부안내 -> 업종분류 현황 메뉴 data 크롤링
def get_stock_data():
url = "http://data.krx.co.kr/comm/bldAttendant/getJsonData.cmd"
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'}
data = {"bld": "dbms/MDC/STAT/standard/MDCSTAT03901", # 주소에 넘겨줄 값
"mktId": "STK",
"trdDd": f"{datetime.date.today().strftime('%Y%m%d')}", # datetime.date.today().strftime('%Y%m%d')
"money": "1",
"csvxls_isNo": "false", }
response = requests.post(url, headers=header, data=data).json() # 주소에 값을 전달해주고 값을 받아 json으로 만든 부분!
return response
def insert_oracle(response):
dsn = cx_Oracle.makedsn("localhost", 1521, 'xe') # oracle 주소를 입력
db = cx_Oracle.connect('SCOTT', 'TIGER', dsn) # oracle 접속 유저 정보
cur = db.cursor()
for i in response['block1']:
value_list = list(i.values())[:8] # 오라클에 넣을 값
try:
cur.execute("INSERT INTO STOCK VALUES(:1, :2, :3, :4, :5, :6, :7, :8)", value_list)
db.commit()
except:
pass
db.close()
def select_oracle():
dsn = cx_Oracle.makedsn("localhost", 1521, 'xe') # oracle 주소를 입력
db = cx_Oracle.connect('SCOTT', 'TIGER', dsn) # oracle 접속 유저 정보
cur = db.cursor()
cur.execute("SELECT STOCK_NAME, INDUSTRY_TYPE, FLUCTUATION, MARKET_CAPITALIZATION FROM STOCK") # oracle에서 만든 stock table에서 필요한 column들만 추출!
column = ["STOCK_NAME", "INDUSTRY_TYPE", "FLUCTUATION", "MARKET_CAPITALIZATION"] # dict 만들려고 컬럼명 만듬
rows = cur.fetchall() # SQL 결과를 받아옴
data = [] # dict를 저장할 빈 리스트 선언
for row in rows:
list_row = list(row)
list_row[2] = float(list_row[2])
list_row[3] = int(list_row[3].replace(',', ''))
data.append(dict(zip(column, list_row))) # column과 row를 묶어 dictionary를 만들어 data에 append함
data_json = {}
data_json['data'] = data
# json형식으로 파일 만들기 처리!
with open("../stock.json", "w", encoding='utf-8') as f:
json.dump(data_json, f, ensure_ascii=False)
def mongo_import():
os.system('mongoimport --db stock -c stock --file stock.json')
def mr_return():
client = MongoClient('localhost', 27017) # mongo 접속
db = client.stock # stock db접속
res = db.stock.aggregate([
{"$unwind": "$data"},
{"$group": {"_id": "$data.INDUSTRY_TYPE", "sum": {"$sum": "$data.MARKET_CAPITALIZATION"}}}
])
res2 = db.stock.aggregate([
{"$unwind": "$data"},
{"$project": {"_id": 0}}
])
result = []
for i in res2:
result.append(i['data'])
with open("../stock.csv", 'w', encoding='utf-8') as f:
wr = csv.DictWriter(f, fieldnames=result[0].keys())
wr.writeheader()
wr.writerows(result)
return res
def plotlyOnly():
df = pd.read_csv('stock.csv')
df = pd.DataFrame(data=df)
fig = px.treemap(df,
path=['INDUSTRY_TYPE', 'STOCK_NAME'],
values='MARKET_CAPITALIZATION',
color='FLUCTUATION', color_continuous_scale='RdBu_r'
)
fig.data[0].texttemplate = "%{label}<br>등락률(전일대비):%{customdata}"
fig.show()
if __name__ == '__main__':
response = get_stock_data()
insert_oracle(response)
select_oracle()
mongo_import()
mr_return()
plotlyOnly()============================================================================
재미는 있었지만 솔직히 다른 조의 결과물과는 차이가 심했다. 같은 시간을 쓴게 맞나?